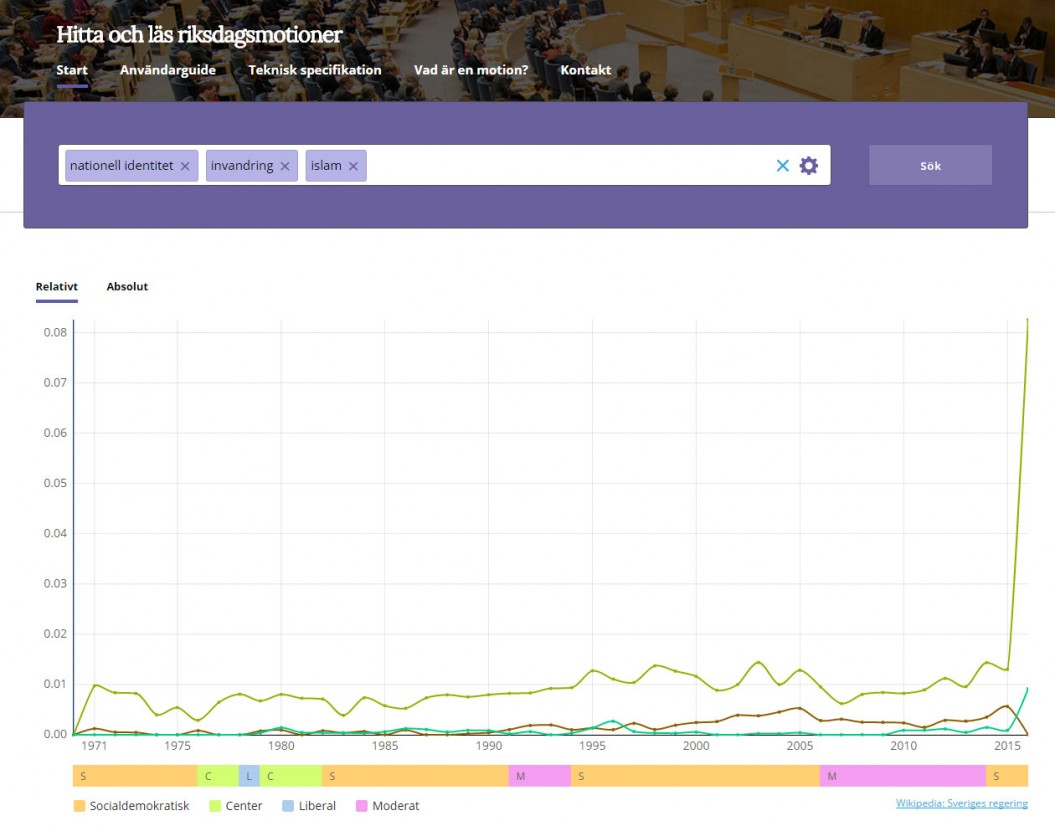
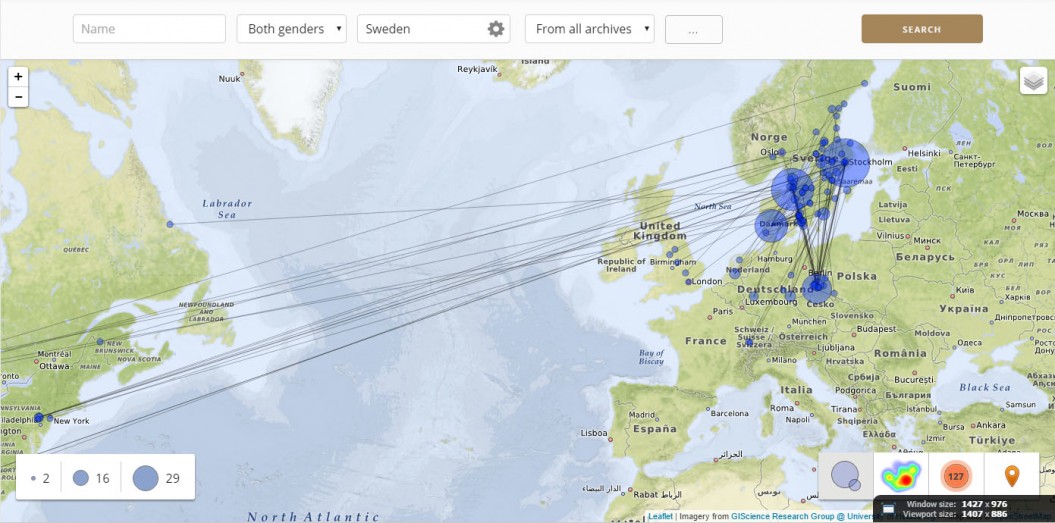
The National Library of Sweden started to harvest the web in 1997. One part of the archive consists of bulk harvesting of the Swedish web. The collection includes both web servers located under the Swedish top level domain “se” and servers located elsewhere. This second part is identified as Swedish using geolocation. Harvesting is done […]
The National Library of Sweden started to harvest the web in 1997. One part of [...]